Human coders are still better than LLMs
▼This is a short story of how humans are still so much more capable of LLMs. Note that I'm not anti-AI or alike, you know it if you know me / follow me somewhere. I use LLMs routinely, like I did today, when I want to test my ideas, for code reviews, to understand if there are better approaches than what I had in mind, to explore stuff at the limit of my expertise, and so forth (I wrote a blog post about coding with LLMs almost two years, when it was not exactly cool: I was already using LLMs for coding and never stopped, I'll have to write an update, but that's not the topic of this post).
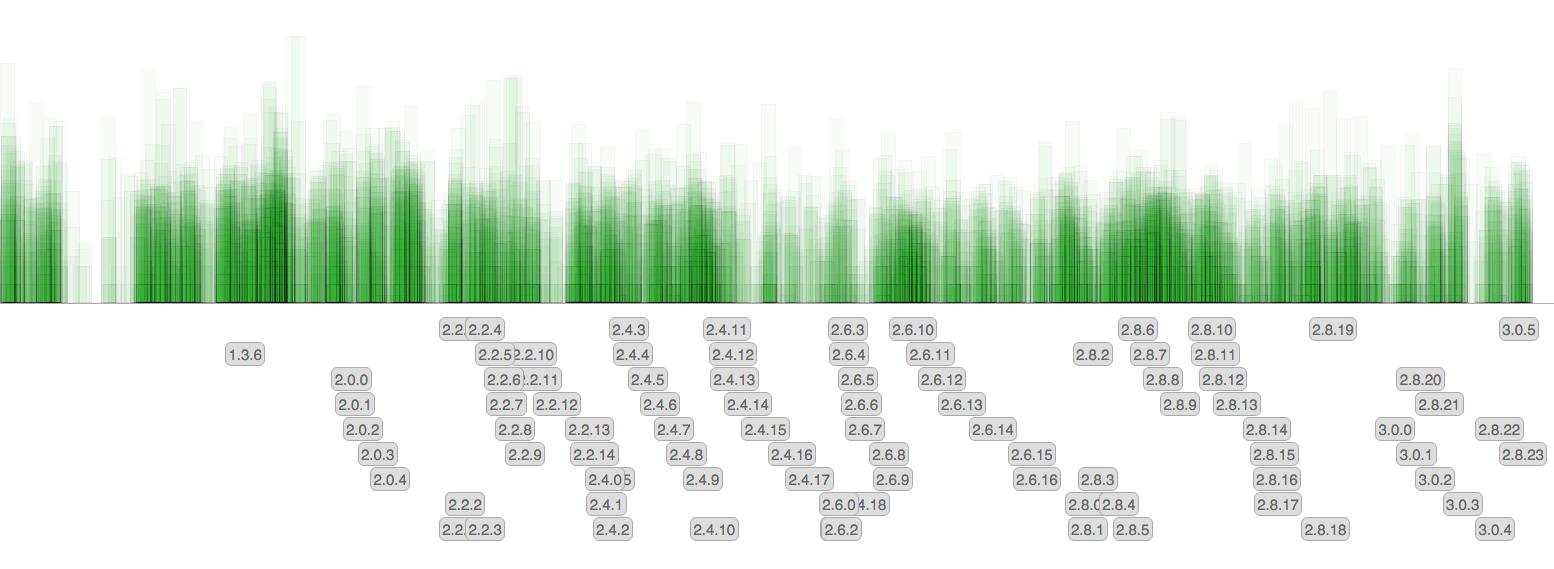 Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.
Each commit is a rectangle. The height is the number of affected lines (a logarithmic scale is used). The gray labels show release tags.
There are little surprises since the amount of commit remained pretty much the same over the time, however now that we no longer backport features back into 3.0 and future releases, the rate at which new patchlevel versions are released diminished.